J'ai donné plusieurs cours d'introduction à la visualisation d'informations à destination de doctorants et de chercheurs. Seul le cours généraliste est mis à jour de façon régulière.
Depuis 2012, je donne tous les ans un cours d'introduction à la visualisation d'information, limité aux visualisations statiques. Le cours n'a pas de lien avec l'apprentissage automatique et est accessible à tous publics (il est prévu pour 2 à 3 heures de présentation). Il se focalise sur les aspects perceptifs de la visualisation d'information. Les transparents en français sont ici (dernière mise à jour : 4 octobre 2016).
Ce cours est une mise à jour du cours de 2007, avec une introduction plus technique que dans la version précédente. Les transparents (en anglais) sont disponibles en deux parties : la nouvelle introduction et une reprise des parties 3 à 5 du cours de 2007 (ce deuxième fichier fait 24 mo) ;
Il s'agit de mon cours le plus complet, donné à l'école doctorale CIL en 2007. Il est prévu pour au moins 6 heures de cours et est présenté de façon détaillée ci dessous.
Ce cours est une introduction à la visualisation de l'information destinée à des chercheurs et doctorants en intelligence artificielle et apprentissage automatique. Il a été donné en février 2007 dans le cadre de l'école doctorale Computational Intelligence and Learning. Il s'agit d'un cours d'ouverture, dont le but est de montrer les liens la visualisation de l'information et les problèmes rencontrés en apprentissage automatique, en particulier dans deux domaines, la classification (non supervisée) et la réduction de dimension (sélection de variables, projection non linéaire, etc.). L'un des problèmes majeurs de la visualisation d'information est en effet celui de la montée en charge : comment représenter des objets nombreux et/ou décrits par de nombreuses caractéristiques ? En proposant des techniques pour résumer (au sens large) un ensemble d'objets, l'apprentissage automatique offre un ensemble de solutions à ce problème.
Bien que ce cours soit destiné à une école doctorale, les pré-requis techniques sont généralement relativement faibles, en particulier dans les premières parties. Il est cependant vivement conseillé de savoir en quoi consiste la classification (non supervisée).
Le cours est organisé selon une logique issue des taxonomies de méthodes de visualisation proposées dans la littérature. Après une introduction, trois grandes parties sont chacune consacrées à une (ou plusieurs) grande(s) classe(s) de méthodes de visualisation. Pour chaque classe, le cours décrit les méthodes puis donne des exemples de problèmes rencontrés pour lesquels des solutions peuvent être trouvées grâce à des outils issus de l'apprentissage automatique ou de l'intelligence artificielle. Il présente aussi des solutions issues de la communauté visualisation, notamment basées sur l'intervention de l'utilisateur. Le cours se termine par une dernière partie consacrée aux méthodes de visualisation issues de la communauté apprentissage automatique.
La première partie aborde ainsi les diagrammes de dispersion, une des représentations les plus utilisées. Elle montre que cet outil souffre de deux limitations : il ne s'applique qu'à des objets de faible dimension (de 2 à 5 caractéristiques par objet) et est confronté à un problème important de superposition des objets.
Ces deux problèmes peuvent être contournés partiellement grâce à des outils de l'apprentissage automatique. Les méthodes de projection (non) linéaire permettent de réduire le nombre de dimension des objets, alors que les méthodes de classification conduisent à la fabrication de résumés des objets.
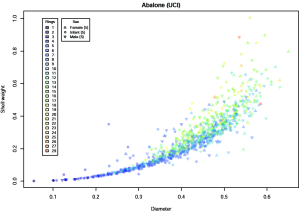
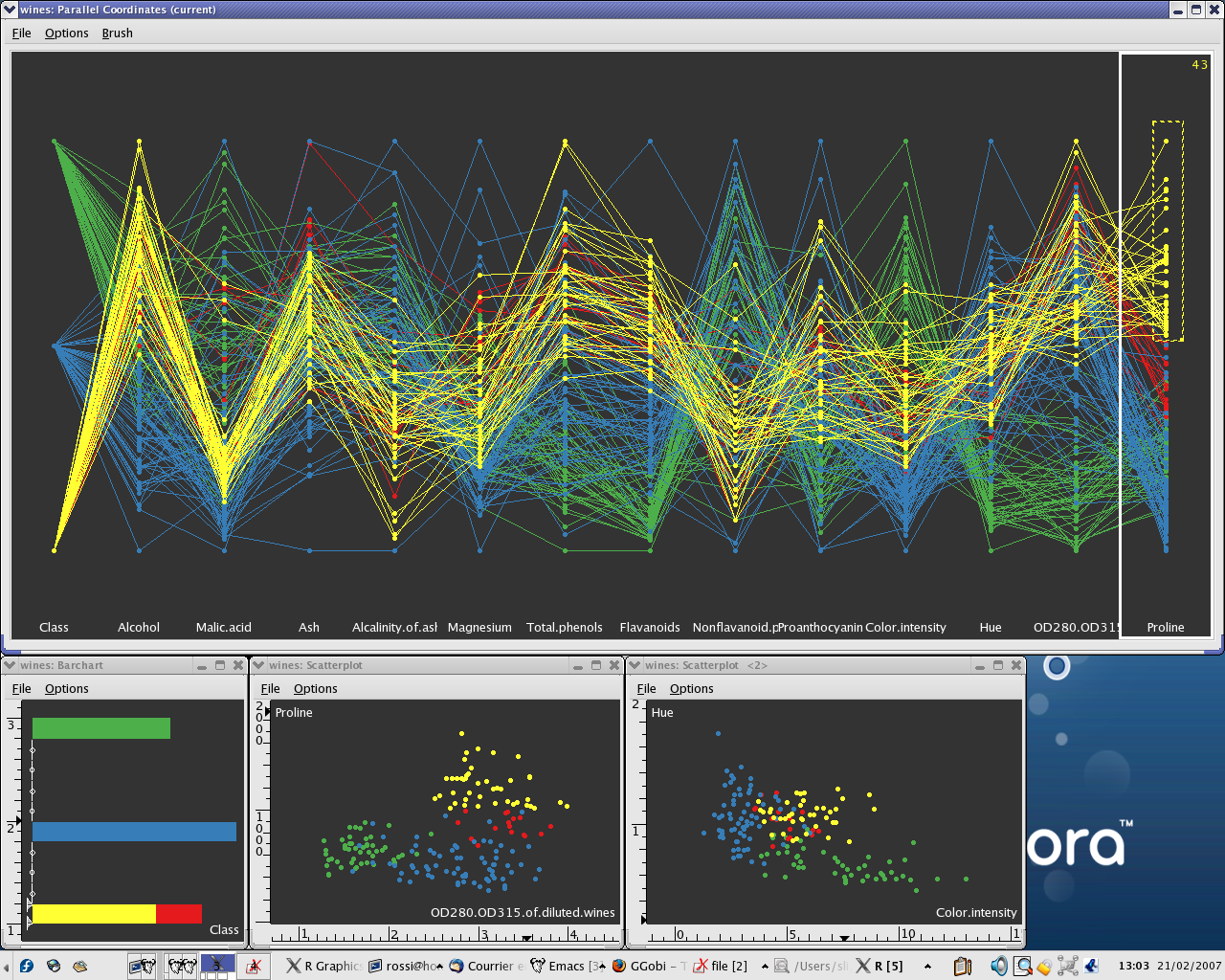
Cette partie est consacrée à des méthodes d'affichage qui réalisent une sorte de projection des données vers un espace de 2 dimensions, d'une façon qui ne dépend pas des données elles-mêmes. Il s'agit en fait d'une transformation statique des données. Le cours se focalise sur les matrices de diagrammes de dispersion (Scatter plot matrices) et sur le système des coordonnées parallèles (Parallel coordinates).
Outre les problèmes de passage en grande dimension et de superposition déjà évoquées, cette partie du cours est l'occasion d'introduire un problème très général en visualisation, celui du choix d'un ordre dans les données utilisé pour déterminer l'ordre de présentation des informations à l'écran. Le cours évoque des solutions automatiques proposées dans le cadre de l'analyse des données
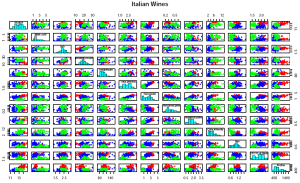
La troisième partie présente deux classes de solutions opposées pour résoudre les problèmes de montée en charge déjà évoqués. L'utilisation d'icônes consiste à remplacer le simple point d'un diagramme de dispersion par un dessin relativement complexe représentant un objet de façon riche. Les solutions basés sur les pixels consistent au contraire à limiter au maximum la place perdue à l'écran en associant à chaque valeur numérique de l'ensemble de données un unique pixel. Dans les deux solutions, on retrouve les problèmes de positionnement et d'ordination évoqués plus tôt.
Cette dernière partie présente brièvement des méthodes de visualisation issues directement de la communauté de l'apprentissage automatique. Il s'agit essentiellement des cartes auto-organisatrices de Kohonen (le Self Organizing Map) et des méthodes à variables latentes (comme le Generative Topographic Mapping).


Les transparents sont en anglais et assez volumineux en raison des images incluses.
 Français
Français  English
English